¿Qué es AWS S3?
AWS S3 es el acrónimo de Simple Storage Service, el servicio de almacenamiento de objetos de Amazon Web Services. S3 lleva funcionando desde el año 2006 y va a ser objeto de este capítulo del curso de AWS.
¿Qué es almacenamiento de objetos?
Tomemos como ejemplo nuestro ordenador, ya sea Windows, Mac o Linux. Dentro de el tenemos una estructura de directorios en los que se almacenan archivos. El sistema operativo accede a ellos directamente. Podemos crearlos, borrarlos, editarlos, cambiar solo un trozo de los mismos.
En AWS, los archivos se almacenan en forma de objetos. Esto quiere decir que si queremos tener un nuevo archivo en S3, debemos subirlo. Si queremos visualizar un archivo de S3, debemos descargarlo. Es como una capa intermedia que se coloca entre nosotros (o los usuarios de nuestro servicio) y el almacenamiento donde se alojan estos archivos.
Podemos alojar en S3 documentos, fotos, vídeos, archivos comprimidos. Sin embargo, al tener esa capa extra de interacción, no podemos alojar en S3 directamente archivos como bases de datos o aplicaciones.
AWS S3 usa unas entidades llamadas buckets para almacenar tus objetos. Bucket es cubo en inglés, así que podemos pensar en los buckets como recipientes en los que metemos archivos.
Características de AWS S3
Capacidad
AWS S3 permite subir una cantidad de archivos ilimitada. Los archivos pueden ocupar hasta 5 Terabytes, pero podemos subir literalmente tantos bytes como queramos.
- ¿Entonces puedo subir mi colección de 200 Terabytes de películas?
- Por supuesto. Luego no te asustes con los 5000 dólares mensuales que te costará tenerlas subidas en S3 🙂
Nombres únicos
Los buckets de S3 tienen un nombre, igual que cualquier carpeta/directorio de tu ordenador. El nombre del bucket debe ser único en toda la plataforma AWS. No me refiero a dentro de tu cuenta, si no a todo AWS en todo el mundo. Es decir, Si yo creo en mi cuenta un bucket llamado «hola», nadie mas en todo el mundo va a poder crear un bucket llamado «hola». Es lo que se conoce como universal namespace.
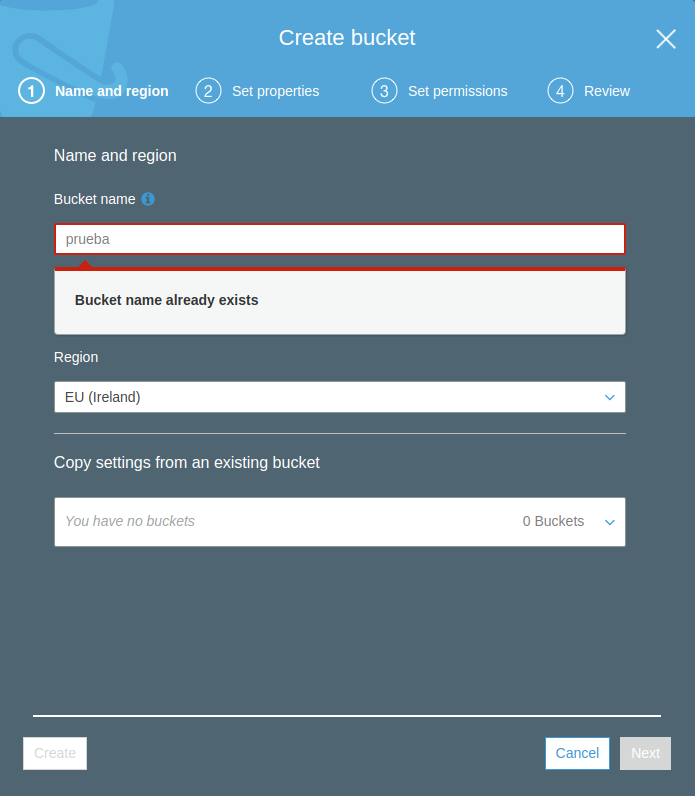
Arriba puedes ver un ejemplo de como el nombre de bucket «prueba» está obviamente en uso y no me permite crearlo dentro de mi cuenta vacía.
Clave Valor
S3 es un almacenamiento de tipo clave – valor. Por decirlo de una forma simplificada, es como una base de datos NoSQL en la que se almacenan las propiedades de diferentes objetos.
{
"Nombre": "Nombre-completo-con-ruta-del-archivo",
"Datos": "Los datos propiamente del archivo, en bytes",
"Version": "La version si tenemos activado el versionado",
"Tags": "diferentes etiquetas que hayamos asignado al archivo"
}
Es importante saber que, pese a que de cara al usuario existen las carpetas o directorios, S3 es un almacenamiento en el que no existe este concepto. La consola web o el cliente de linea de comandos simulan el comportamiento de un sistema de ficheros, pero realmente el archivo /directorio1/directorio2/directorio3/nombrearchivo.txt se corresponde con un archivo en tu bucket llamado directorio1-directorio2-directorio3-nombrearchivo.txt
Recordemos que nuestros objetos los subimos a un bucket s3 cuyo nombre debe ser único. El nombre de tu archivo en S3 entonces será:
NombreDelBucket/directorio1-directorio2-directorio3-nombrearchivo.txt
Seguridad en S3
Podemos definir políticas de acceso para los objetos y buckets de S3. Cuando creamos un bucket en S3, éste y sus contenidos solo son accesibles por el propietario de la cuenta AWS que lo ha creado. Si queremos dar acceso a otras personas o incluso universal, debemos configurarlo manualmente.
Nivel de servicio de AWS S3
El servicio AWS S3 tiene diferentes niveles de durabilidad y disponibilidad (y cobran diferente por cada uno).
S3 Estándar
Es el nivel de servicio por defecto de AWS S3. Ofrece una disponibilidad del servicio del 99.99% aunque AWS solo garantiza por escrito el 99.9%. Estos números quieren decir lo siguiente. En el caso del 99.99% de disponibilidad, implica que el servicio puede estar caído hasta 52 minutos al año. No quiere decir que se vayan a perder los datos, si no que puede que durante casi una hora al año no se pueda acceder a los archivos.
99.9% es un número mucho más conservador y es el que AWS garantiza por escrito. Corresponde con hasta casi 9 horas de servicio no disponible al año.
La durabilidad de los datos es de 99.999999999% (once nueves). Los datos se almacenan en múltiples dispositivos de almacenamiento y replicados en al menos 3 zonas de disponibilidad. El servicio S3 está diseñado para que los datos puedan sobrevivir incluso si se pierden dos datacenters de AWS de forma simultánea. El tiempo de acceso cuando queremos descargar un archivo es de milisegundos.
S3 Infrequent Access
S3 Infrequent Access surgió de la necesidad de almacenar archivos que no necesitan ser accedidos de forma frecuente, pero en caso de ser necesario, deberían estar disponibles inmediatamente. Pongamos como ejemplo las facturas de compra de un cliente. Es muy raro que en una visita de un cliente vaya a descargarse facturas pasadas. Sin embargo, en caso de querer hacerlo, deben estar disponibles para que se las descargue en el momento que quiera. El coste de almacenamiento en S3 IA es inferior, pero cobran por el volumen de datos que se descarga y la facturación mínima por almacenamiento de archivos es de 30 días. Además, la disponibilidad del servicio garantizada pasa de 99.9% a 99% y la deseada de 99.99% a 99.9%. La durabilidad es la misma que en S3 standard.
S3 One Zone Infrequent Access
S3 One Zone Infrequent Access es la modalidad más económica de AWS S3 (un 20% menos que S3 IA) que permite limitar la redundancia de los datos a una única zona de disponibilidad. Si la zona de disponibilidad donde se almacenan nuestros datos cae, los datos no serán accesibles. Esto puede ser util para almacenar datos a los que accedemos poco y que además, somos capaces de regenerar de otra forma. Por ejemplo: Si tenemos una miniatura de nuestras fotos, podemos almacenarlas en este tipo de almacenamiento. Como disponemos de nuestras fotos en formato original, podríamos regenerar las miniaturas de nuevo en caso de que se perdiese la AZ de Amazon donde se almacenan nuestras miniaturas.
S3 Glacier
Glacier es un servicio de almacenamiento seguro pensado en el archivado de datos. La forma más común de pensar en Glacier es como un servicio de backup a cintas magnéticas. Los datos no están accesibles inmediatamente, y pueden tardar varios minutos y normalmente horas en ser accesibles. Para acceder a datos almacenados en Glacier, hemos de enviar una petición de recuperación expresa, que podemos acelerar si pagamos un extra por gigabyte. Hay que tener claro que los datos que enviemos a Glacier son necesarios durante al menos 90 días, ya que es el periodo mínimo que nos van a facturar por lo que almacenemos allí.
Transiciones y ciclo de vida S3
Los objetos de S3 pueden transicionar de un tipo de almacenamiento a otro en función de su edad. Podemos configurar que un objeto S3 empiece estando en almacenamiento S3 estándar y pasado un mes, sea movido a S3 Infrequent Access. Pasados 3 meses podemos pasarlo a S3 One Zone Infrequent Access y finalmente pasado un año, moverlo a Glacier. Hay que tener presente siempre que el acceso a objetos movidos a Glacier es bajo demanda y con un tiempo alto de recuperación.
Replicación de objetos y eventos
Recordemos que los objetos de S3 se distribuyen entre los distintos datacenters de AWS. Hay que tener un par de consideraciones sobre la consistencia de estos datos cuando subimos o borramos archivos de S3.
AWS S3 ofrece consistencia inmediata tras realizar una subida de un objeto nuevo. (PUT)
AWS S3 ofrece una consistencia eventual para sobreescrituras de objetos y borrados de objetos. Es posible que la actualización de un archivo tarde un tiempo en propagarse a todas las copias que S3 tiene de el. De cualquier manera, el objeto no puede estar medio actualizado. O se sirve la versión antigua o la nueva, pero en ningún caso se serviría una a medio modificar. De la misma manera, si borramos un objeto, puede que durante un tiempo (hasta unos minutos) siga estando disponible si se sirven las peticiones desde un datacenter que aun no haya aplicado ese borrado en su copia local.
Costes de AWS S3
Cuando interactuamos con el servicio de almacenamiento S3 de AWS, nos facturarán por:
- Tamaño de los objetos que guardamos
- Peticiones, tanto de subida como de bajada de archivos.
- Ancho de banda consumido al transferir los objetos de S3.
- Etiquetas usadas para categorizar los objetos.
Interacción con AWS S3
Para interactuar con S3 podemos hacerlo de 3 maneras.
- API HTTP. Debemos usar la API REST. Existe una API SOAP antigua que no incorporará las nuevas funcionalidades de AWS S3.
- AWS CLI. El cliente de línea de comandos.
- Consola web AWS. Nos permite subir, descargar y eliminar archivos en S3.
Podemos descargar archivos directamente usando HTTPS desde un navegador siempre que sean accesibles mediante una politica adecuada.
Podemos descargar archivos desde S3 mediante el protocolo Bittorrent. A pesar de que normalmente nos viene a la cabeza la descarga de peliculas cuando mencionamos bittorrent, este protocolo es muy ventajoso para distribuir las descargas de archivos entre varios nodos. Al usar bittorrent para ofrecer la descarga de un archivo que tenemos en S3, permitiremos que la transferencia de datos se distribuya también a otros usuarios de bittorrent que ya tengan descargado ese archivo. Esto ayudará a reducir los costes por transferencia de datos en AWS S3.
Preguntas frecuentes de AWS S3
La sección de preguntas frecuentes de AWS S3 contiene información que aparece de forma frecuente en el examen y conviene conocer. Aqui dejo el enlace a la sección FAQ de S3.
Trabajando con S3
Como crear un bucket S3
Vamos a crear un bucket S3. Para ello, tenemos que hacer login en la consola web AWS. En servicios, seleccionamos S3 dentro del apartado de Storage.
Una vez estamos en el panel de S3, podemos fijarnos que arriba a la derecha, donde suele aparecer la región de AWS en la que estamos trabajando, aparece Global. Esto ocurre con otros servicios de AWS y quiere decir que estamos trabajando con un servicio que tiene un namespace universl. Es decir, lo que hagamos en este servicio no es dependiente de la región o simplemente es una funcionalidad en la que la región no tiene razón de ser.

Para crear nuestro bucket S3 vamos a pulsar en el botón Create Bucket. Recuerda que el nombre debe ser único en todo AWS, incluidas los otros millones de cuentas de otros usuarios así que no intentes crear un bucket llamado «prueba» o «test».
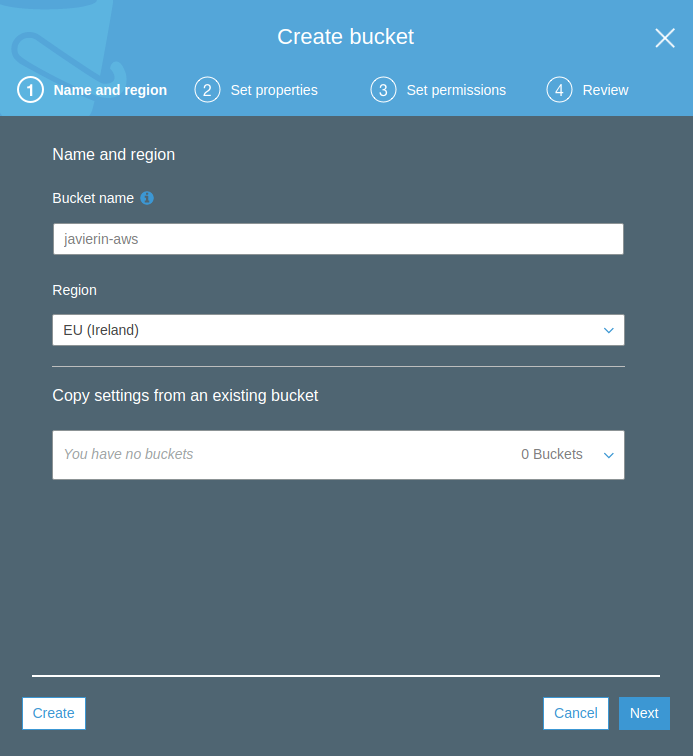
En el siguiente paso podemos habilitar una serie de opciones para versionado, logging y categorización del bucket mediante etiquetas. Dejaremos eso para más adelante.
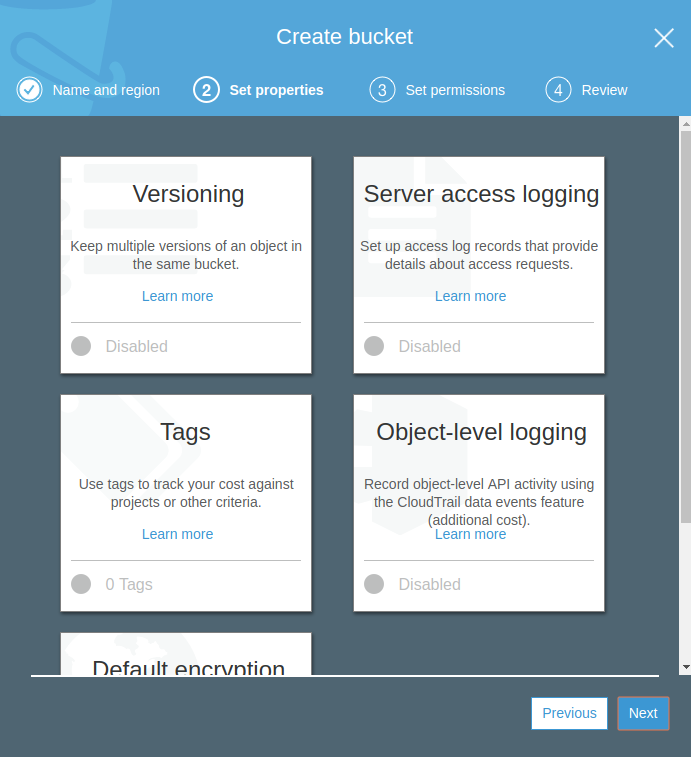
El siguiente paso es establecer los permisos. Como antes comentamos, los buckets de S3 son privados por defecto y tenemos que especificar manualmente si queremos que se accesible por el mundo entero, otros usuarios AWS u otros usuarios de nuestra propia cuenta de AWS. La última opción habilita los permisos para que el sistema de logs de AWS pueda usar este bucket como un almacenamiento de destino para logs.
Si pulsamos Next veremos un resumen de las opciones que hemos seleccionado antes de crear finalmente el bucket.
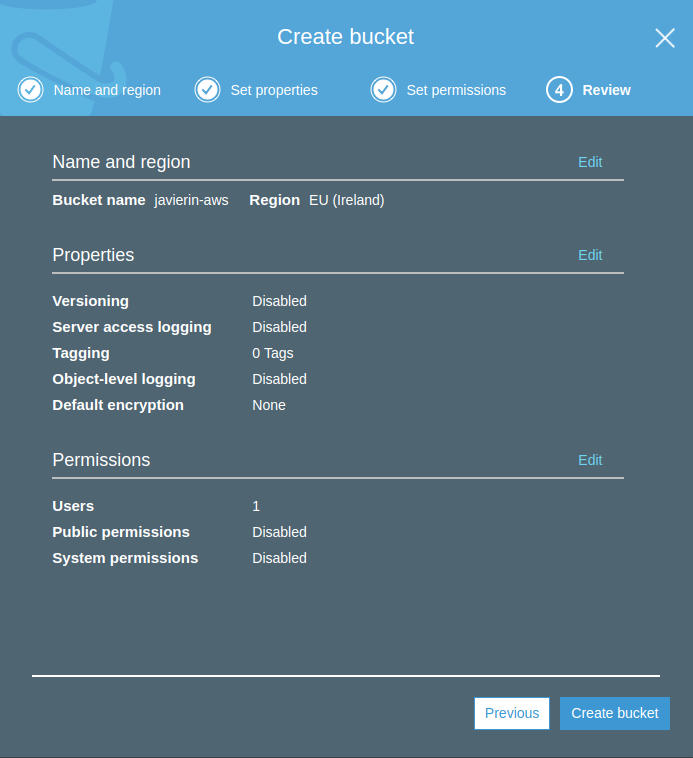
Como subir archivos a AWS S3
El siguiente paso ahora que hemos creado nuestro bucket es subir algun archivo. Para ello haremos click sobre el nombre del bucket para acceder a su contenido.

Una vez dentro, pulsamos en Upload File y seleccionamos los archivos que queramos subir. En el mismo dialogo podemos ver en todo momento el bucket de destino al que estamos realizando la subida.
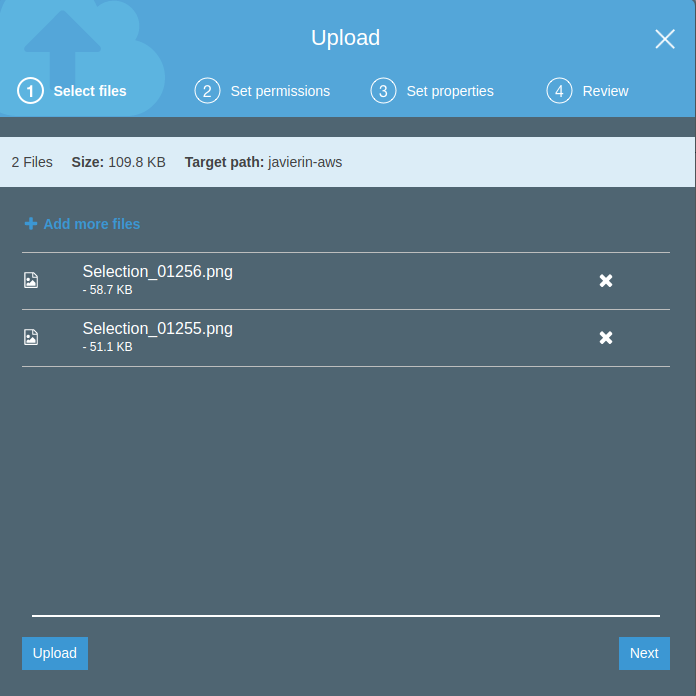
Al pulsar Next llegharemos a la parte de los permisos. De momento lo dejaremos tal y como está y seguiremos hacia adelante hasta terminar con el asistente de subida.
Una vez se hayan subido los archivos nos aparecerán en la lista. Si echamos alguno en falta podemos usar el botón de actualizar que hay a la derecha de la consola de S3 (lo encontrarás resaltado en la siguiente captura de pantalla)
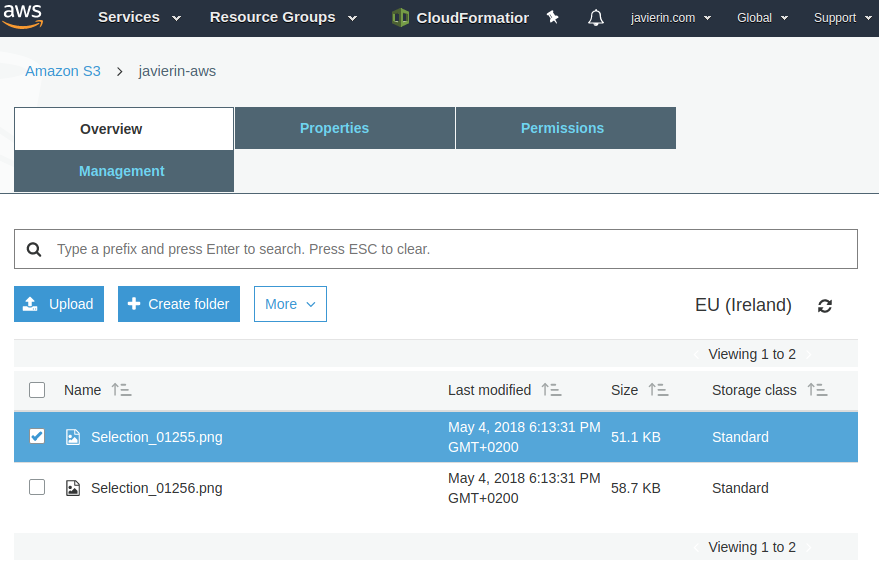
Recuerdas que antes dijimos que una de las formas de acceder a los archivos de S3 es mediante HTTPS desde un navegador cualquiera? Hagamos click en uno de los archivos que acabamos de subir y nos fijaremos en donde pone «Link». Ese enlace HTTPS es un acceso directo a la imagen que acabo de subir. Vamos a abrirlo en una pestaña nueva del navegador.
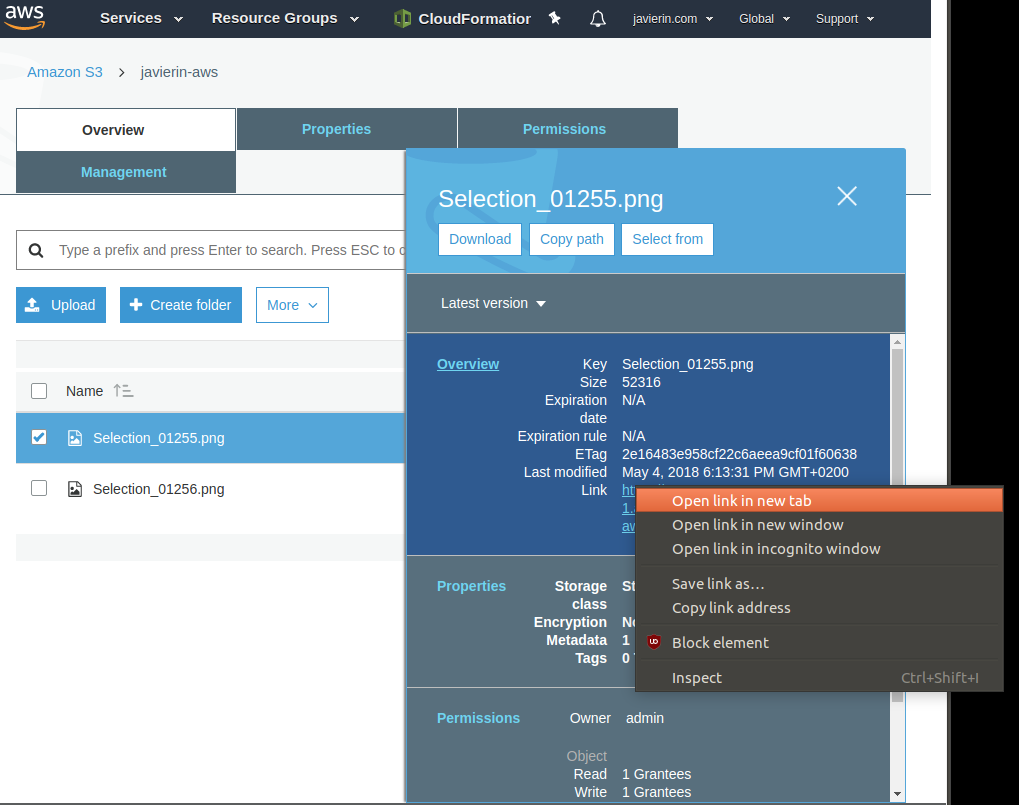
Ooops! Error. Permiso denegado!

¿Qué ha pasado? Pues que como antes comentamos, todos los archivos que se suben a S3 tienen por defecto permisos solo para el propietario dentro de la consola AWS. Al intentar acceder al archivo desde fuera de la consola AWS, no nos identifica como propietarios del mismo y entramos en la categoría «todo el mundo» que, por el momento, tiene prohibido el acceso a nuestros datos.
Vamos a solucionarlo y dar permisos a todo el mundo para que pueda leer ese archivo concreto. Haremos click con el botón derecho del ratón sobre el archivo y seleccionaremos Make Public.

El siguiente diálogo nos informa de que vamos a hacer accesible a todo Internet el archivo (o archivos) seleccionados. Si seleccionamos una «carpeta», ocurriría lo mismo. Pulsemos el botón Make Public.
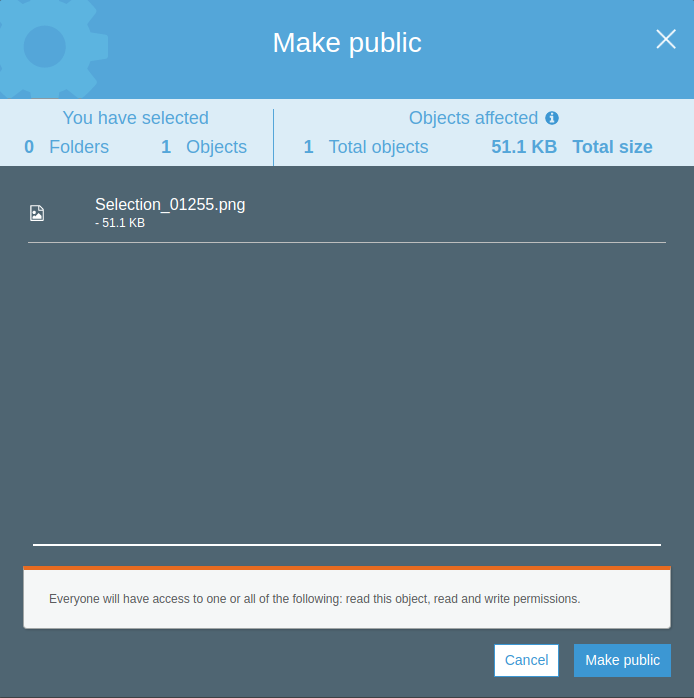
Si ahora volvemos a seleccionar el archivo y abrimos su enlace HTTPS en una pestaña nueva, ya no recibiremos el mensaje de permiso denegado.
Propiedades de objetos AWS S3
AWS ofrece la posibilidad de cambiar con enorme granularidad los objetos que almacenamos en nuestros buckets. Para ello podemos hacer click sobre el nombre del archivo del que queremos revisar las propiedades. Se nos abrirá un panel en el que tenemos las pestañas Overview, Properties y Permissions.
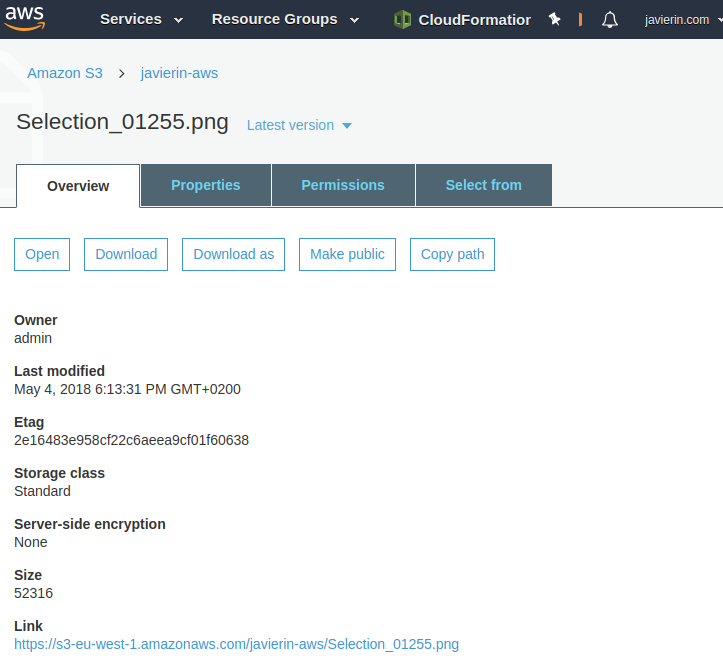
En Overview nos encontraremos información sobre el archivo o carpeta. También tendremos un enlace al objeto mediante HTTPS. Vamos a la pestaña Properties que tiene más interés.
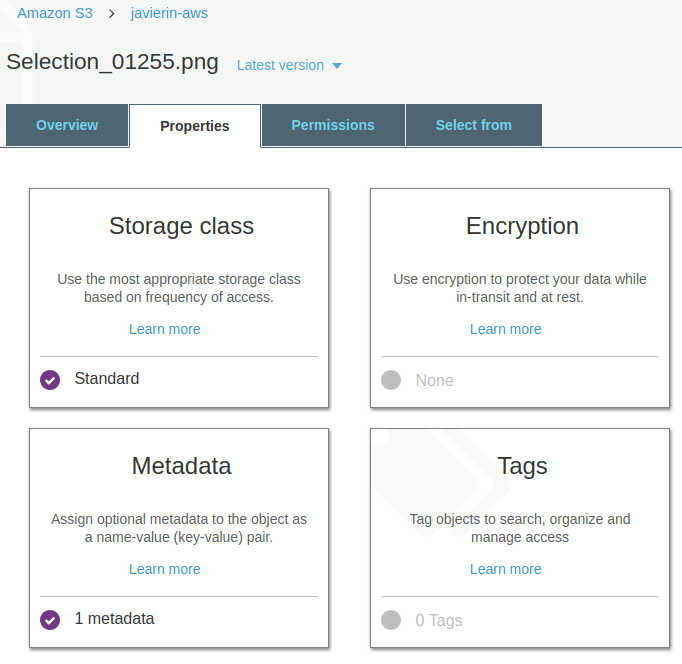
En este panel nos encontramos con cuatro tarjetas diferenciadas.
Storage Class
Esta propiedad permite elegir que calidad de servicio S3 queremos para nuestro objeto. Ya antes vimos los cuatro tipos de almacenamiento S3 que había disponibles. Por defecto, se usará el Standard. Vamos a cambiarlo a reduced redundancy ya que se trata de un archivo que solo nos interesa para hacer los ejercicios. Fíjate bien en como te avisan de que Infrequent Access tiene una retención mínima de 30 días. Es decir, lo que muevas a almacenamiento tipo Infrequent Access se añade a la factura automáticamente como si lo hubieses tenido allí 30 días. El mensaje sobre los 128KB no es muy acertado. Lo que quieren decirte realmente es que cada objeto que muevas a almacenamiento Infrequent Access, contará mínimo desde 128KB. Si mueves un millón de archivos de 0 bytes a almacenamiento S3 IA, pagarás por lo que ocupan un millón de archivos de 128KB en esa categoría de precios de S3.
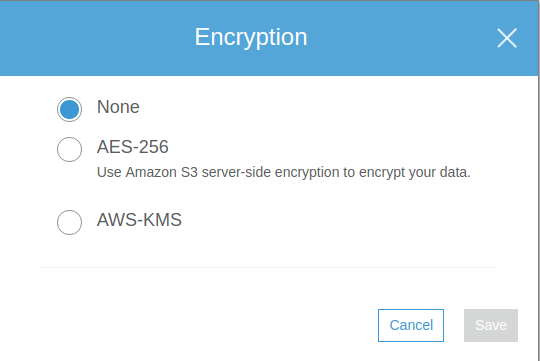
Encriptación
El cifrado o encriptación de los datos que quieres aplicar a tus archivos. Puedes seleccionar una clave generada por Amazon AWS o bien usar una clave tuya que tengas almacenada en el servicio AWS KMS.
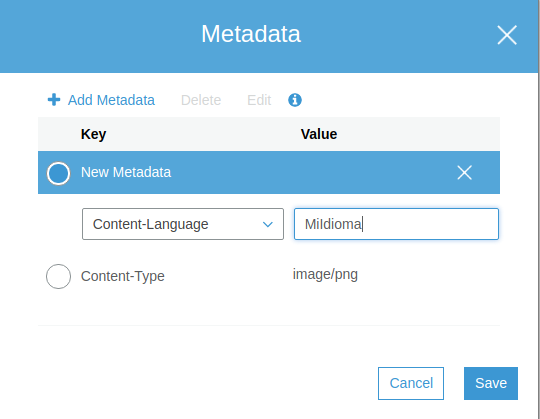
Metadatos
Un conjunto de etiquetas que queremos asignar al archivo y que se devolverán al navegador cuando se haga una petición HTTPS solicitando ese recurso. Voy a añadir una etiqueta totalmente inutil a la imagen con el objeto de ver como se incorpora a la respuesta del servidor HTTP de S3.
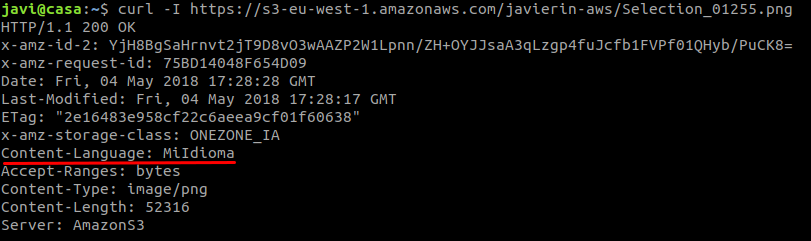
Fíjate como S3 devuelve una serie de etiquetas que revelan que almacenamos nuestro archivo en almacenamiento tipo OneZone Infrequent Access. Fíjate como también ha incorporado la etiqueta que acababa de añadir.
Iremos a la pestaña Permissions y podremos ver como se ha agregado un permiso de solo lectura para Everyone.
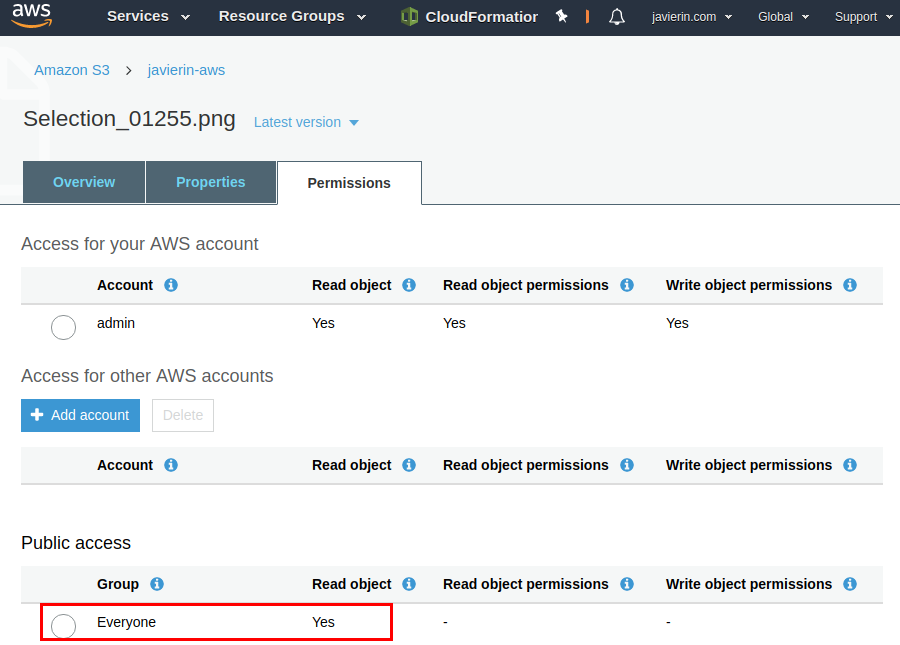
Del mismo modo podemos agregar permisos en esta misma pestaña para que otra cuenta de AWS tenga permisos sobre el objeto.
Propiedades de buckets s3
Del mismo modo que podemos establecer unas propiedades para los objetos que almacenamos en los buckets de s3, podemos igualmente establecer una configuración para cada bucket. Para ello haremos click en la parte superior, donde tenemos el nombre del bucket y seleccionaremos la pestaña Properties.

Aqui podremos encontrarnos diversas opciones que podemos habilitar de forma global en el bucket.
Versionado
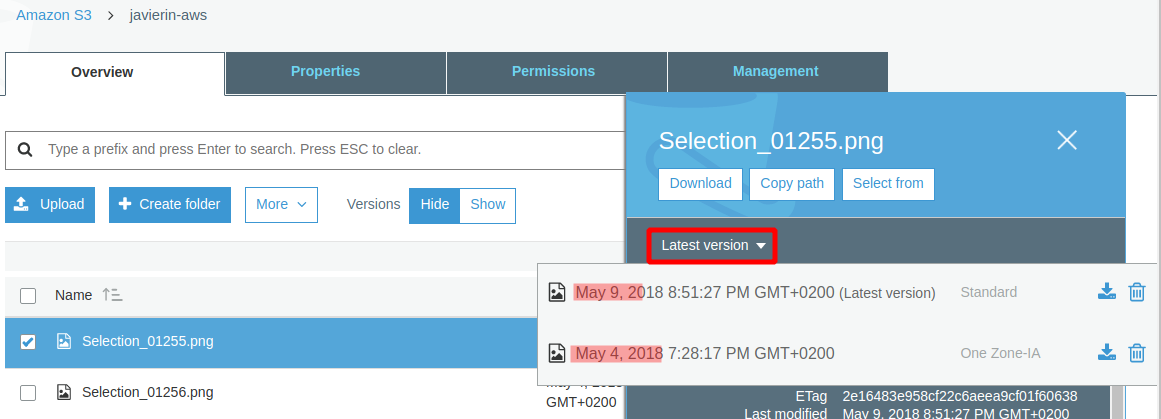
El versionado es una forma de guardar todo el historial de cambios que sufre un archivo. Si vamos cambiando un archivo y lo subimos a S3 sobreescribiéndolo, teniendo activo el versionado podremos recuperar cualquiera de las revisiones que haya ido teniendo el objeto. Para acceder a las diferentes versiones del archivo, seleccionamos el archivo y vamos a donde pone Latest Version, que nos mostrará que versiones anteriores tenemos disponibles y en que tipo de almacenamiento se guardan.
Logging
En la opción de logging podemos habilitar registros de actividad detallados de nuestro bucket S3. Deberemos seleccionar el bucket de destino en el que queremos que se guarden estos logs así como un prefijo para los archivos de logs generados.

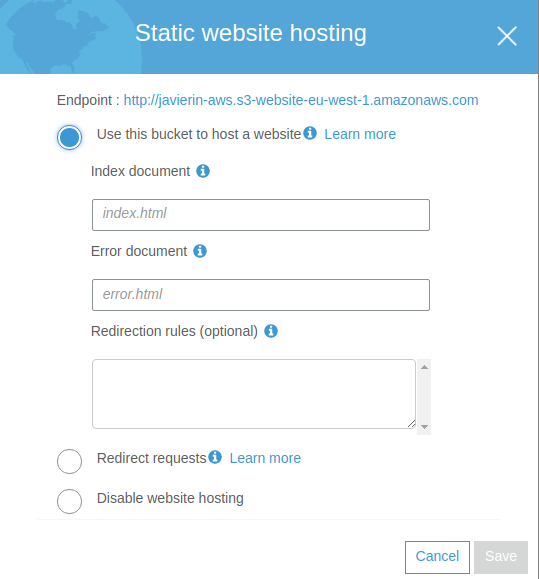
Static Website Hosting
Con esta opción podemos alojar un sitio web estático, sin ningún tipo de código ejecutable en el lado del servidor. S3 se encargará de servirlo en la URL que nos proporciona. Es posible incluir reglas de redirección en un formato que puedes encontrar especificado aqui.
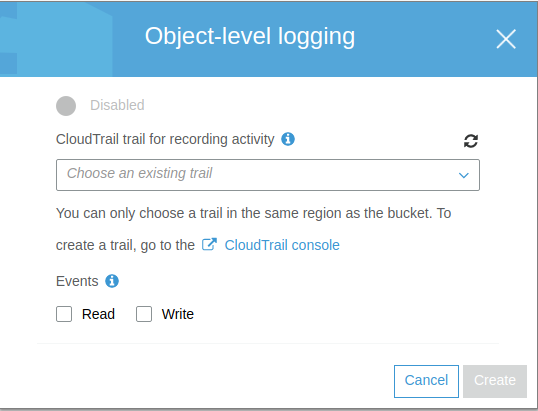
Object Level Logging
Si tuvieramos configurado Cloud Trail, que veremos más adelante, podríamos enviar registros de eventos sobre los objetos que almacenamos en S3.
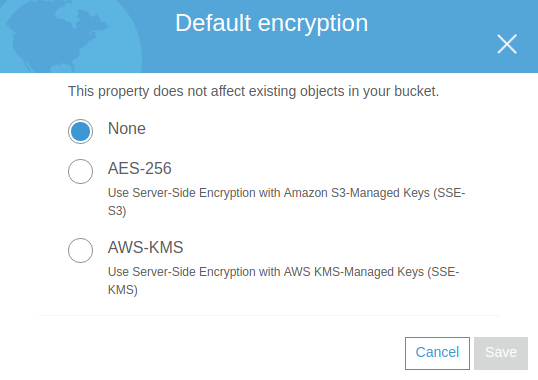
Default Encryption
Permite especificar si queremos cifrar mediante AES256 o una key proporcionada por nosotros todos los objetos que se suben a este bucket S3.
Opciones avanzadas de buckets S3
Podemos configurar opciones más avanzadas que no todo el mundo necesita de forma tan habitual. Sin embargo, la primera de todas me parece fundamental y es una excelente práctica usarla.
Tags
El uso de Tags, etiquetas, me parece fundamental en toda infraestructura S3. Permite buscar rápidamente instancias, buckets, servicios. También permite categorizar los gastos apropiadamente. Añadir etiquetas como Cliente con valor NombreDeCliente nos facilitará la vida en un futuro cuando queramos saber por ejemplo cual es el coste que nos supone un cliente en nuestra infraestructura.

Transfer Acceleration
Esta es una funcionalidad que solo recomiendo a quienes suban de forma constante archivos de gran tamaño a S3. La esencia de este servicio es ofrecer la oportunidad de usar los nodos más cercanos de AWS Cloudfront para subir nuestros archivos a S3. AWS se encarga de forma posterior de llevarlos por su red interna (mucho más optimizada) hasta la región de destino de S3 que usemos. Se entiende mucho mejor con un caso práctico:
Disponemos de una cámara de videovigilancia instalada en una oficina de Tokyo que genera 50 Gigabytes de vídeo cada hora y necesito guardar en S3 una copia de esos vídeos. Por requisitos legales, solo puedo almacenar mis vídeos dentro de la comunidad Europea. La opción habitual sería realizar la subida desde Tokyo hasta el bucket de S3 situado en Irlanda directamente, pero la velocidad de transferencia sería bastante reducida. Con S3 Transfer Acceleration, subiríamos el vídeo a un nodo local de Cloudfront en Tokyo y AWS lo trasladaría a Irlanda usando sus interconexiones internas, que son mucho más rápidas y directas. ¿La diferencia de velocidad? Juzga tu mismo.
